
Amazon Redshift : le data warehouse en mode cloud d'AWS
Amazon Redshift, c'est quoi ?
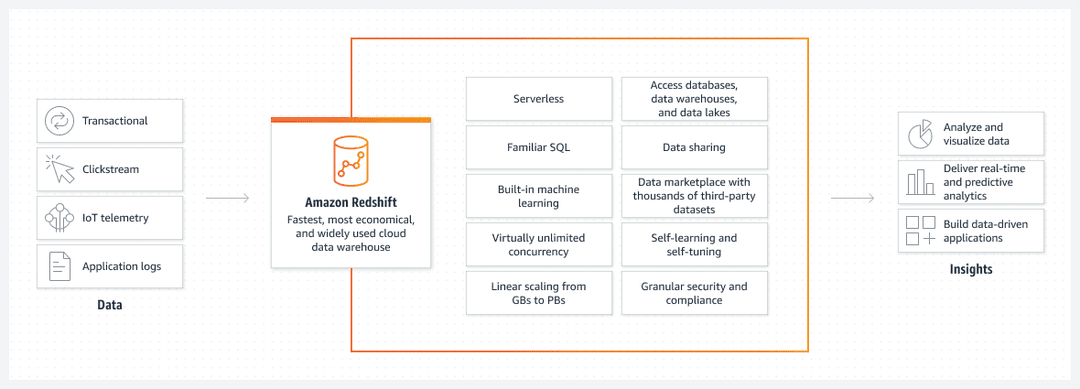
Lancé en octobre 2012 par AWS, Amazon Redshift est un service de data warehouse entièrement managé. Reposant sur un système de gestion de base de données (SGBD) en colonnes, il propose un traitement massivement parallèle.
Conçu pour les charges de travail analytiques, Amazon Redshift gère des volumes de données de l’ordre du pétaoctet (1015 octets). Basé sur le moteur PostgreSQL, un standard open source du marché, l'entrepôt de données dans le cloud s’intègre à la plupart des applications tierces via les protocoles ODBC (open database connectivity) et JDBC (java database connectivity). Cette offre complète d’autres services d'AWS de gestion de bases relationnelles (SimpleDB et Amazon RDS) ou non relationnelles (DynamoDB).
Quels sont les cas d'usage d'Amazon Redshift ?
Amazon Redshift fournit l'infrastructure nécessaire pour des requêtages rapides en langage SQL. Désigné pour le traitement de données hautes performances, Redshift permet de créer, entraîner et déployer des modèles de machine learning. Amazon Redshift sert les outils de business intelligence pour créer des rapports et des tableaux de bord personnalisés.
Amazon Redshift est-il une base de données relationnelle (SQL) ?
Amazon Redshift est un système de gestion de base de données relationnelle compatible avec les autres SGBDR du marché. A la différence de bases de données traditionnelles, le service d'AWS stocke les données en les regroupant par colonnes et non par lignes. Dédié au big data, un SGBDR orienté colonnes permet d’obtenir des temps de réponses rapides à des requêtes complexes.
Amazon Redshift Serverless
Amazon Redshift Serverless est l'option sans serveur d'Amazon Redshift. L'approche serverless décharge l'utilisateur de la configuration et de la gestion de l'infrastructure. L'entrepôt de données se met à l'échelle automatiquement en fonction de la charge de travail.
Avec Amazon Redshift Serverless, l'utilisateur se contente de charger les données dans la base avant de pouvoir les interroger ou les partager. Sur la base du paiement à l'usage, la facturation s'établit à la seconde.
Qu'est-ce qu'Amazon Redshift Spectrum ?
Redshift Spectrum est une fonctionnalité d'Amazon Redshift conçue pour lancer directement depuis Redshift des requêtes sur des données structurées ou semi-structurées stockées sur le service de stockage objet Amazon S3. Elle permet d'interroger ou récupérer ces données en évitant de les charger au sein de tables Redshift, y compris depuis plusieurs cluster Redshift simultanément.
Redshift vs Athena
Alors qu'Amazon Redshift est entrepôt de données, Amazon Athena n'est qu'un service de requêtage taillé pour interroger ou analyser des données structurées ou semi-structurées stockées sur Amazon S3.
Redshift vs RDS
Là où Amazon RDS (pour Relational Database) est une plateforme de données relationnelle, Amazon Redshift, lui, se présente sous la forme d'un entrepôt de données structuré différemment, à savoir en colonnes. Ce qui lui permet de traiter des volumes massifs de données avec une plus grande vélocité.
Redshift vs Aurora
Contrairement à Redshift qui est un entrepôt de données structuré en colonnes, Amazon Aurora est un système de gestion de base de données relationnelle (RDBMS). Compatible avec MySQL et PostgreSQL, Aurora est proposé dans le cadre de l'offre Amazon RDS.
Redshift vs EMR
Amazon EMR (ex-Amazon Elastic MapReduce) n'est autre qu'une plateforme reposant sur des instances EC2 conçue pour exécuter les infrastructures big data open source Apache Hadoop et Apache Spark. Egalement taillé pour les traitements big data, Redshift est un entrepôt de données structuré en colonnes développé directement par les équipes d'Amazon Web Services.
Redshift vs Snowflake
Comparé à la plateforme de données Snowflake, le principal avantage de Redshift réside évidemment dans son intégration avec l'offre cloud d'AWS. Vis-à-vis de Redshift, le point fort de Snowflake est de découpler le stockage du calcul. Résultat : il permet d'encaisser des pics de trafic en accroissant la capacité de calcul sans voir à augmenter le volume de stockage.
Amazon Redshift documentation
Sur son site, AWS propose une documentation technique fournie sur Redshift en français, avec à la clé plusieurs guides et tutoriels :