
Scikit-learn : bibliothèque star de machine learning Python

Qu’est-ce que Scikit-learn ?
Initié et piloté en France par l'INRIA et Télécom ParisTech, le projet Scikit-learn est devenu une référence dans le monde de l'intelligence artificielle. De Paris à San Francisco en passant par Singapour, la bibliothèque open source de machine learnin Python, s'impose aux start-up jusqu'aux grands groupes, Gafam compris. Elle est disponible sous licence BSD.
Scikit-learn recouvre les principaux algorithmes de machine learning généralistes : classification, régression, clustering, gradient boosting... En parallèle, le framework embarque NumPy, Matplotlib et SciPy, trois librairies star du calcul scientifique qui en font un outil très prisé au sein de la communauté des chercheurs rompus au calcul matricielle.
Quel est le point fort de Scikit-learn ?
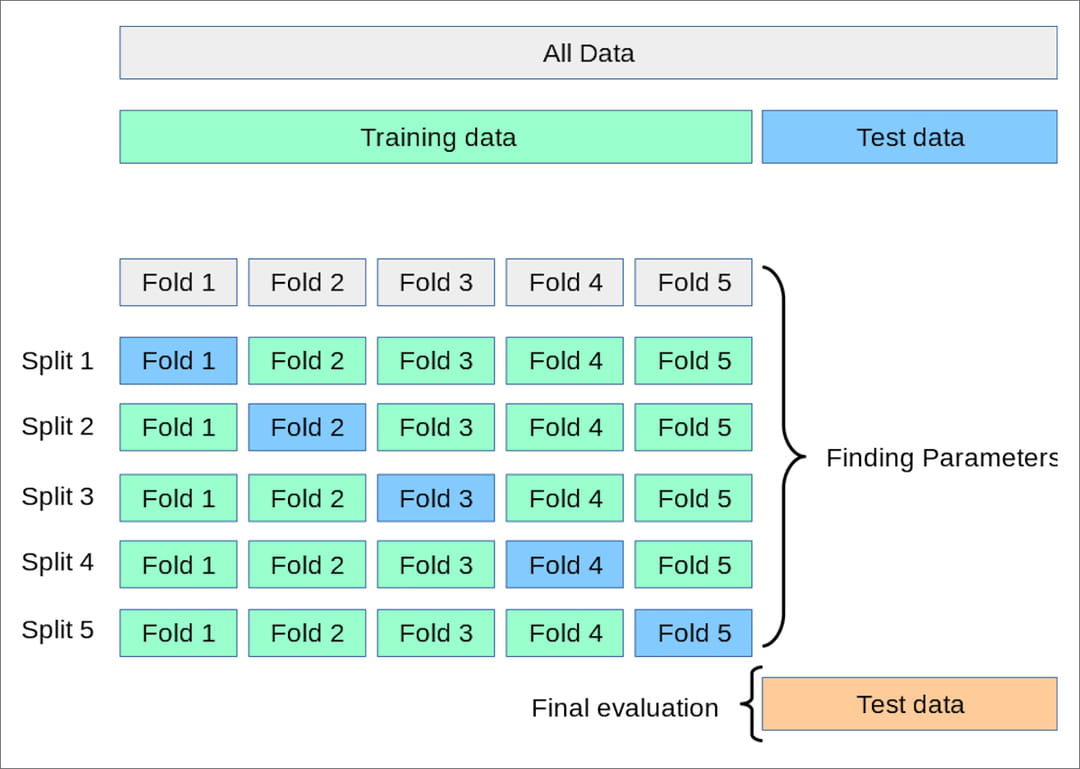
Parmi ses facteurs de différentiation, Scikit-learn est plébiscitée pour sa méthode de validation croisée. En amont, elle fournit la possibilité de générer très simplement les bases d'entrainement et de test. Ensuite via un mécanisme de grid search, la validation croisée permet de dénicher les paramètres du modèle se rapprochant le plus des prédictions attendues. Le processus ajuste l'échantillonnage de la base de test en la confrontant à la base d'apprentissage par itérations successives (voir schéma ci-dessous). L'objectif est d'aboutir au bon réglage en termes de seuils, par exemple ne pas dépasser 2% en matière de détection de fraudes.
Autre point fort de Scikit-learn, la librairie embarque toute une palette de méthodes pour piloter le pre-processing des data sets en amont des phases d'apprentissage. Elles gèrent leur extraction, leur nettoyage, leur formatage et leur labellisation. Cependant, elle propose une intégration limitée avec Pandas. Une librairie qui, lors de cette délicate étape de préparation, permet de manipuler les données sous forme de tableaux plutôt que de matrices comme le fait nativement Scikit-learn. Les deux bibliothèques peuvent néanmoins travailler de concert. Une première passerelle entre Scikit-learn et Pandas est par ailleurs disponible.
L'un des principaux avantages de Scikit-learn est aussi de proposer une documentation claire et didactique avec des exemples d'implémentations et des packages prêts à l'emploi. Tensorflow se révèle beaucoup plus difficile à paramétrer. Le caractère open source de Scikit-learn (avec à la clé un développement communautaire) et sa facilité de prise en main l'ont rendu très populaire.
Quelle est la principale limite de Scikit-learn ?
Scikit-learn souffre d'une faiblesse congénitale à la technologie Python. Ce dernier étant un langage interprété, la librairie ne peut pas offrir les performances d'un langage compilé. Python gère cependant beaucoup mieux la mémoire vive que R, un autre langage star de la data science, orienté statistique. Le Cython résout en partie le problème en ouvrant la possibilité de compiler des composants Python en C ou en C++. Quelques algorithmes sont disponibles dans Scikit-learn pour ce langage. C'est le cas de la famille des SVM (pour Support Vector Machines ndlr). Compte tenu de cet avantage, on pourrait imaginer que d'autres soient implémentés à l'avenir par la communauté.
Quels sont les plateformes d'IA intégrant Scikit-learn ?
Les fournisseurs d'outils d'IA commerciaux ont rapidement vu dans Scikit-learn une potentielle poule aux œufs d'or. L'infrastructure est implémentée par plusieurs poids lourds de la data science dont le Français Dataiku, l'Américain DataRobot et l'Allemand Knime. Elle est aussi prise en charge par un nombre croissant d'acteurs du cloud. C'est le cas de Google via son service Cloud Machine Learning Engine, d'IBM avec Watson Machine Learning ou encore de Microsoft par le biais d'Azure Machine Learning.
Comment télécharger Scikit-learn sur GitHub ?
Scikit-learn est disponible sur GitHub. Il faut se rendre sur la page du framework de machine learning afin d’accéder au fichier. Le lien permet de distinguer les différents modules, extensions et documentations techniques à disposition.
Comment installer Scikit-learn avec PyPI ?
L’installation de Scikit-learn peut se faire depuis un environnement Windows, Linux ou macOS. Afin d’optimiser la compatibilité entre système et framework, il est recommandé de l’installer depuis un gestionnaire de package conçu sous Python. Sous pip qui permet de gérer les packages Python via PyPI (Python Package Index), la procédure d’installation nécessite la ligne de code suivante : "pip install -U scikit-learn". La démarche d'installation pip et les fichiers de téléchargement Scikit-learn correspondants sont accessibles à cette adresse. Pour une installation de Scikit-learn sous Conda, il faut se rendre sur cette page. Le système demande l’entrée "conda install -c anaconda scikit-learn".
Scikit-learn PCA
La bibliothèque Scikit-learn permet de réaliser une analyse en composante principale ou principal component analysis (PCA). Une méthode qui consiste à transformer des variables corrélées en nouvelles variables décorrélées mais moins nombreuses, baptisées composantes principales ou axes principaux.
L'objectif de l'analyse en composante principale est de réduire le volume de variables du modèle de machine learning. En clair, elle permet d'améliorer la performance du modèle en éliminant les variables qui ne contribuent à aucune prise de décision.
Quels sont les modèles inclus dans Scikit-learn ?
Afin de gérer au mieux les projets de data science, Scikit-learn comprend plusieurs modèles et fonctionnalités. On retrouve ainsi :
- Le clustering : un modèle de partitionnement de données qui emploie différents algorithmes, comme k-means ou DBSCAN ;
- La régression linéaire : un modèle de calcul qui s’appuie sur un ensemble de données afin de réaliser des fonctions prédictives ;
- Le classifieur KNN : compatible avec le dataset IRIS, il s’agit d’un modèle qui se base sur une méthode d’apprentissage supervisé ;
- Lasso : un modèle statistique déclinable en modèle linéaire ou en écriture vectorielle. Il met en œuvre une technique de contraction sur les coefficients de régression.
Scikit-learn : documentation et tutoriel
Le site officiel du projet Scikit-learn propose toute une série de contenus pour aider les utilisateurs à aborder la bibliothèque de machine learning :