
Réseau de neurones artificiels : réseaux neuronaux pour l'IA
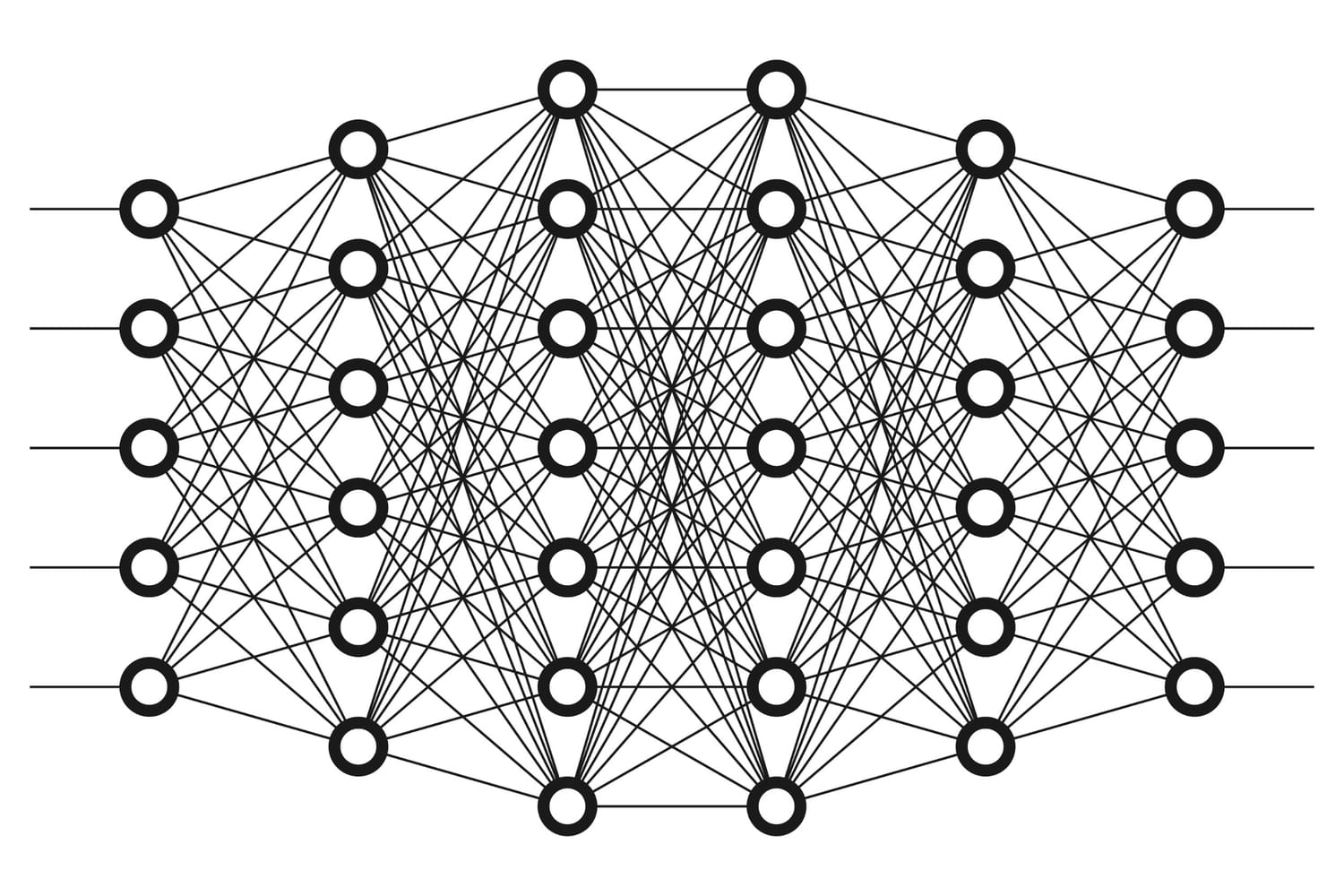
Un réseau de neurones artificiels, c'est quoi ?
Un réseau de neurones artificiels (ou deep neural network) s'inspire de la structure d'un cerveau humain. Il se présente sous la forme d'au moins deux couches de neurones qui, à partir d'un flux de données d'apprentissage, vont interagir pour apprendre à réaliser des tâches. Les réseaux de neurones artificiels s'appliquent à de multiples domaines : la reconnaissance d'images et la vision par ordinateur, la reconnaissance vocale et plus largement au traitement automatique du langage ou natural language processing (NLP).
L'apprentissage profond, ou deep learning, désigne la profondeur des couches d'un réseau de neurones artificiels. En général, on utilisera ce terme dans le cas d'un réseau comportant plus de trois couches.
Comment fonctionne un réseau de neurones artificiels ?
Un réseau de neurones artificiel se compose d'au moins deux couches, chacune contenant plusieurs neurones ou nœuds. D'une couche à l'autre, les nœuds sont liés entre eux. A chacun sont associées des données d'entrée, un poids, un seuil et des données de sortie (dont la valeur est le résultat de la valeur d'entrée du neurones multipliée par le poids de celui-ci). Si les données en sortie d'un nœud vont au-delà du seuil spécifié, ce neurone est activé et envoie ses données aux neurones de la couche suivante. Et un ainsi de suite.
L'apprentissage d'un réseau de neurones artificiels consiste à ajuster de manière itérative les poids associés à chacun de ses nœuds, en partant de petites valeurs. Objectif : minimiser l'écart avec le résultat recherché. Pour réaliser cet exercice, on s'appuiera sur une base d'apprentissage composée de couples associant une donnée d'entrée à une cible à atteindre. A chaque donnée d'entrée soumise, le réseau doit estimer les poids du réseau. Une fonction d'erreur est utilisée pour calculer la différence entre la prévision réalisée et la valeur cible en vue d'ajuster les poids au fur et à mesure. Le processus est répété pour chaque couple de la base d'apprentissage.
Qu'est-ce qu'un réseau de neurones convolutif ?
Inspiré du cortex visuel des vertébrés, un réseau de neurones convolutif ou convolutional neural network (CNN) se compose, comme un réseau de neurones artificiels classique, de couches de neurones successives. Des neurones de traitement appliquent d'abord une fonction de convolution à une partie de l'image, baptisée tuile. Ensuite viennent les neurones de padding, ou de mise en commun, qui réduisent la taille des images intermédiaires, et ainsi la quantité de paramètres et de la puissance calcul associée. Ce qui permet au final d'optimiser l'efficacité du réseau et d'éviter le sur-apprentissage. Entre chaque couche, un traitement correctif non linéaire et ponctuel peut être mis en œuvre pour optimiser la pertinence des résultats.
En termes de machine learning, un réseau de neurones à convolution entre dans la famille des modèles d'apprentissage non-supervisé. Il cerne par lui même les caractéristiques de chaque image issue du data set d'apprentissage. Chacun de ses filtres, ou noyau de convolution, identifiera un motif. De fil en aiguille, la reconnaissance d'image se fera de plus en plus précise. La technique des réseaux convolutifs a été inventée par le français Yann Lecun dans les années 1990.
Un neurone formel, c'est quoi ?
Un neurone formel désigne un neurone artificiel. Le premier neurone formel est inventé par les neurologues Warren McCulloch et Walter Pitts. C'est un neurone binaire dont le résultat vaut 0 ou 1. Pour le calculer, il réalise la somme pondérée de ses entrées représentant la sorties d'autres neurones formels (représentant aussi 0 ou 1) puis applique une fonction d'activation à seuil : si la somme pondérée dépasse une certaine valeur, la sortie du neurone est 1, sinon elle vaut 0.
Warren McCulloch et Walter Pitts montrèrent notamment qu'un réseau composé de plusieurs neurones formels a la même puissance qu'une machine de Turing.
Réseau de neurones convolutif vs perceptron multicouche : quelle différence ?
Un perceptron multicouche (ou multilayer perceptron) est un réseau de neurones artificiels comprenant plusieurs couches qui permet de produire un séparateur non linéaire. Il s'agit d'un réseau à propagation directe de plusieurs couches disposant chacune d'un nombre de neurones artificiels variable.
Un réseau de neurones convolutif se caractérise par un poids unique associé aux neurones d'un même filtre. Un filtre est chargé d'identifier un motif particulier au sein d'une image. Résultat : cette méthode permet de réduire la puissance de calcul nécessaire et d'améliorer les performances globales du réseau. C'est là le principal point fort d'un réseau de neurones convolutifs comparé à un perceptron multicouche qui affecte un poids différent à chaque neurone.