
Feature store (gratuit) : définition et avantage en IA
Le feature store, c'est quoi ?
La notion de feature store est introduite pour la première fois par Uber dans un post publié 2017. Sous ce terme, le VTC désigne le référentiel qu'il utilise pour stocker les caractéristiques de ses modèles de machine learning. L'enjeu ? Faciliter le partage de ces feature de projet en projet. Uber affirme être confronté à de nombreuses problématiques de modélisation impliquant des attributs similaires ou identiques. D'où l'idée de les mutualiser par le biais d'une base de données pivot.
Dans le cadre d'une IA factory, le feature store se révèle central. Il permet de capitaliser sur les fonctions d'apprentissage déjà créées pour les nouveaux développements. Autant de temps de gagné en feature engineering. Dans le domaine de la santé, les features peuvent renvoyer au groupe sanguin d’un individu, à sa courbe de taille, de poids... Le feature store centralise les features et permet de les partager aisément au service d’autres modèles de machine learning.
Exemple de cas d'usage de feature store
Les feature renvoient aux informations utilisées pour alimenter le machine learning. Dans le cas d'une IA de recommandation sur une plateforme de streaming musicale, il s'agit par exemple des morceaux déjà écoutés, de leur durée de lecture ou encore de leur classement en termes d'audience.
Grâce à un outil de feature store, la plateforme de streaming pourra typiquement réutiliser le ranking de trafic utilisé ici pour d'autres modèles, sur le front du ciblage publicitaire par exemple.
Quel est l'avantage d'un feature store ?
Le feature store consolide les workflows de machine learning autour d'un pipeline unique pour l'entrainement, le test et la validation des modèles, ainsi que leur exécution sur le terrain. Il permet de bénéficier d'une seule source de vérité avec une méthode de transformation de donnée unique par feature. Fédérer ainsi les méthodes de transformation facilite leur monitoring et leur validation, et simplifie de facto la traque des biais qui peuvent découler des features ou des données. Le référentiel stocke par ailleurs les métadonnées des features et leur historique. Ce qui permet de conserver la trace des commentaires des data scientists sur l'influence des features sur tel ou tel modèle, et ainsi de mieux identifier les types de problèmes auxquels elles peuvent répondre.

Lors de la phase d'apprentissage, le feature store est également là pour garantir l'intégrité des data sets. "Les données d'entrainement peuvent intégrer par erreur des informations dédiées au test du modèle une fois formé. Ce qui évidemment fausse les résultats. On parle alors de feature leak", explique Ismaïl Lachheb chez Octo Technology. Une telle fuite est vite arrivée. "Dans le cas d'une database avec une dizaine de jointures (entre les tables, ndlr), il suffit d'une erreur sur l'une d'entre elles pour que le set d'apprentissage accède à des données destinées aux test", indique le data scientist. Lors de la création des différents data sets, le feature store se charge de garantir l'étanchéité des données quel que soit le nombre de jointures et de tables utilisées. "Il gère le versionning et l'exécution de l'apprentissage en cohérence avec l'évolution de l'état des data dans le temps", ajoute Sergio Winter, machine learning engineer chez Revolve, entité de Devoteam experte d'AWS.
Dernier grand bénéfice du référentiel de caractéristiques, le feature store assure la standardisation du formatage et du calcul des features entre apprentissage et prédiction en situation réelle. "Si le préprocessing des données n'est pas exactement le même dans les deux cas, un biais d'apprentissage / invocation va apparaître avec un impact négatif sur la qualité des résultats", prévient Ismaïl Lachheb. Un différentiel qui peut provenir d'une négligence ou d'une gestion des sources de données d'apprentissage et d'inférence par des équipes différentes. En contrôlant le featuring des données à la fois lors de la prédiction et de l'entraînement, le référentiel de caractéristiques assure la cohérence entre les deux sources.
Quels sont les outils de feature store ?
Pour se lancer, il existe plusieurs outils open source de feature store. Les plus populaires sont :
- Feast,
- Hopsworks,
- Tecton.
Tecton a été créé par les développeurs à l'origine de la plateforme d'IA d'Uber (lire l'article Comparatif des feature store : Tecton surplombe Feast et Hopsworks).Du côté des clouds, Amazon Web Services (AWS) et Google commercialisent également des référentiels de caractéristiques managés. L'offre d'AWS présente l'avantage de s'intégrer à Data Wrangler. "A la différence de Cloud Dataprep de Google (qui repose sur une application tierce signée Trifacta, ndlr), c'est un outil graphique qui ne gère pas seulement le batch mais aussi les transformations de données et la mise à jour des data sets en temps réel", compare Sergio Winter (lire l'article Plateformes cloud d'IA : Amazon et Microsoft distancés par Google).
Feature Store de Databricks
Databricks propose sa propre plateforme d'IA : Databricks Machine Learning. Taillée pour tourner sur l'infrastructure de l'éditeur conçue pour fédérer big data analytics et machine learning, elle intègre notamment un feature store.
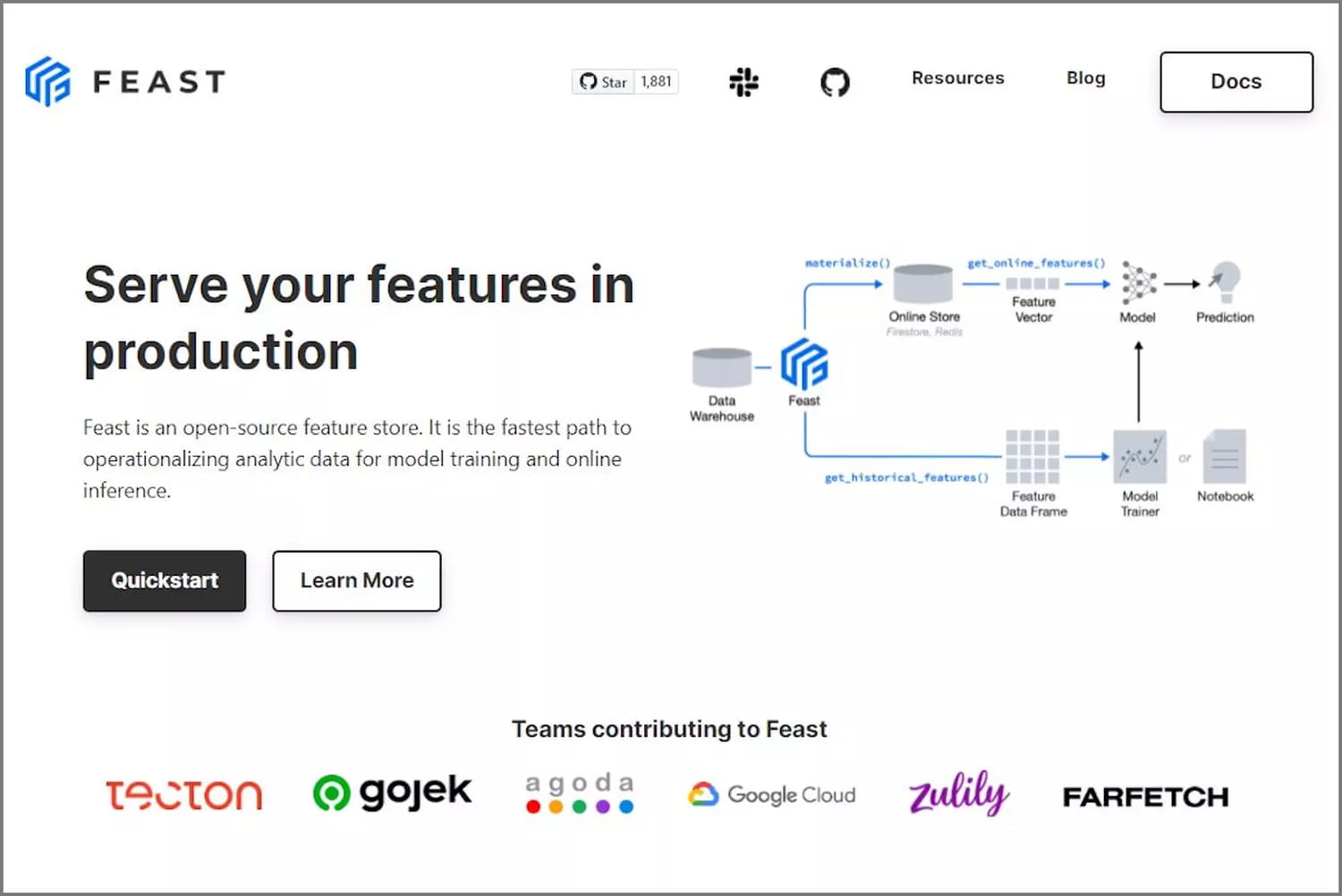
Feast : feature store open source
Feast est une librairie open source de gestion de features. Cette librairie permet notamment de définir des features stores pour aider à la construction de modèles et à la récupération de données.
Feature store vs data warehouse
Un data warehouse est un entrepôt de données (ou EDD). Il s’agit d’une base de données relationnelle qui a vocation à recueillir des données issues de sources très diversifiées. Sa principale fonction consiste à valider une analyse et optimiser le processus de prise de décision d’une entreprise.
Le feature store est en quelque sorte un data warehouse (orienté fonctionnalités) au service du machine learning. Le feature store est différent d’un point de vue architectural, dans la mesure où il s’agit d’une double base de données avec chacune ses particularités :
- Une base de données qui contient des données distribuées par le kit de développement logiciel (ou SDK = Software Development Kit), avec une grande profondeur temporelle.
- Une base de données qui contient des données récentes et des données en streaming, cette BDD (base de données) est plus rapide pour servir les données "fraîches".